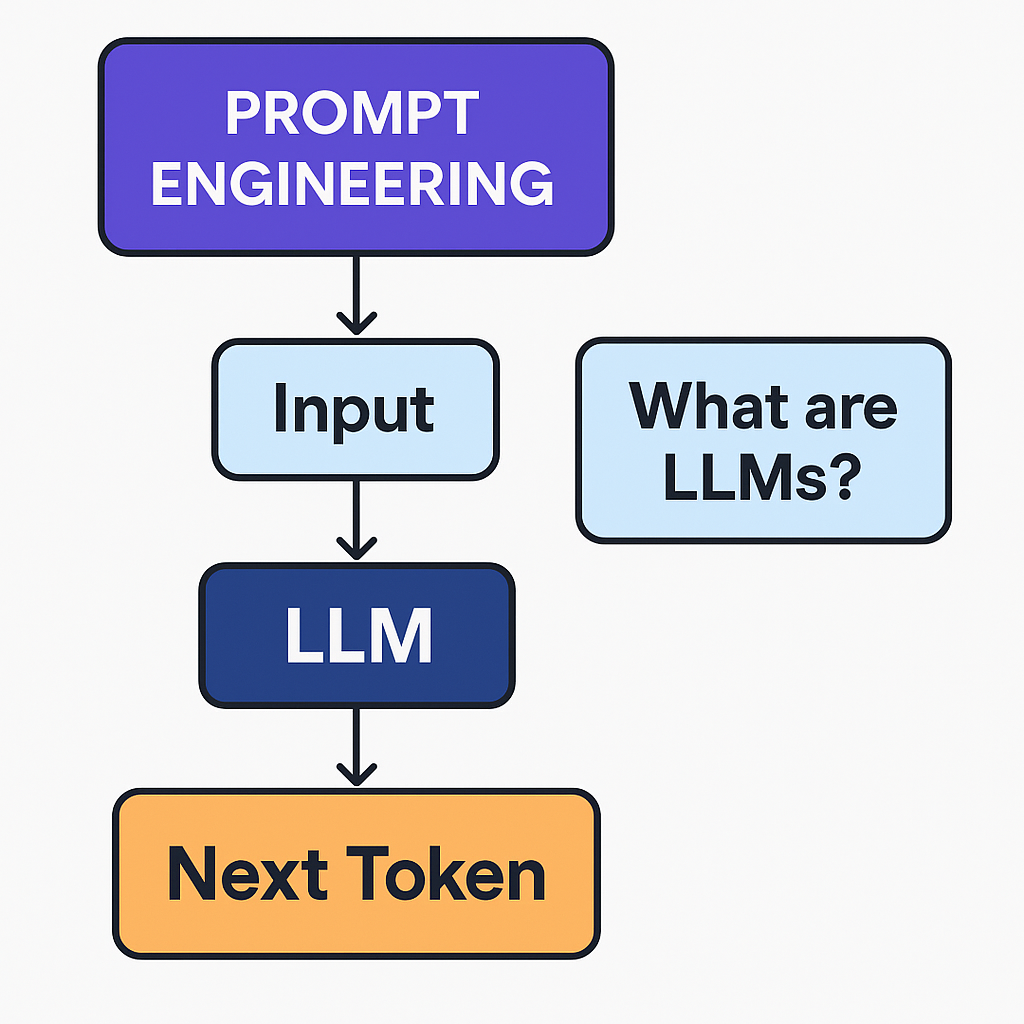
LLMs Are Just Token Predictors
Large language models (LLMs) like GPT-4, Claude, and others have become popular tools, but it’s important to understand how they really work.
At their core:
They are just high-dimensional probabilistic models trained on language. Their goal is to generate the next token based on a history of previously generated tokens.
A token can be a word, part of a word, a character, whitespace, or other pieces of text.
They generate text sequentially — predicting the most probable next token using the input prompt. Once a token is generated, it gets appended to the input and used to predict the next token. This continues until a stop condition is met.
Note: Because we are predicting the next token based on the previous predicted value this process is called auto-regression. Therefore latter parts of a response is generally worse. This is called exposure bias in sequence models.
Pseudocode Example: What is the Capital of Canada?
# Input: user query (a string)
prompt = "What is the capital of Canada?"
# Tokenize the prompt into input IDs (tokens)
input_tokens = tokenizer.encode(prompt) # e.g., [101, 2003, 1996, 3007, 1997, 2605, 1029]
# Initialize the output with just the prompt tokens
context_tokens = input_tokens.copy()
# Prepare a list to store generated tokens
generated_tokens = []
# Loop until stopping condition (e.g., end-of-sequence or max tokens)
while not stop_condition(generated_tokens):
# Model predicts the next token based on current context
next_token = model.predict_next_token(context_tokens)
# Append to generated tokens
generated_tokens.append(next_token)
# Extend the context so the model conditions on everything so far
context_tokens.append(next_token)
# Decode only the generated part (not the prompt)
generated_text = tokenizer.decode(generated_tokens)
# Final output
print(generated_text)But make no mistake:
The model doesn’t know what it’s saying — it’s just estimating the next plausible continuation based on the prompt. That’s why prompt engineering isn’t a novelty — it’s the mechanism through which we define behavior.
Prompt Engineering
Treat prompting like software engineering.
LLMs don’t infer your intent unless you specify it. They don’t handle ambiguity well unless they’ve seen enough similar ambiguity during training. If your output isn’t accurate, structured, or grounded, the cause is likely the prompt — not the model.
Let’s look at a simple task: extracting data from a conversation.
Naive Prompt
List important papers on prompt engineering.
This will likely return something, but it’s unconstrained, underspecified, and fragile.
Structured Prompt
Please provide a list of real and verifiable academic papers on prompt engineering published in the last 5 years.
- Include the full citation (authors, title, publication, year).
- Return the results as a JSON array with fields:title,authors,publication,year.
- If no verified papers are found, respond with: “No verified papers found.”
- Do not fabricate or guess any information.
This is prompting as interface design: constraints, format, logic, and outcome — all specified up front.
On “Hallucination”: It’s Often You, Not the Model
Yes, LLMs can hallucinate. But the term is overused and often misunderstood.
Most hallucination isn’t a model defect — it’s an instruction defect.
The model doesn’t know what’s real. If your prompt doesn’t instruct it to be grounded, cite sources, or defer when uncertain, it will continue the text using its training priors — even if that means fabricating.
Why RAG Changes the Game
One of the most common reasons LLMs hallucinate is because they don’t have access to your knowledge.
That’s where Retrieval-Augmented Generation (RAG) becomes critical.
RAG combines an LLM with a retrieval layer, injecting contextual documents at inference time.
This lets the model ground its responses in data that was never part of its training — internal knowledge bases, product manuals, recent documents, etc.
The process looks like this:
- Query → Embedding + Similarity Search → Relevant Docs
- Retrieved docs get passed into the prompt
- LLM answers the question using the injected context
This solves hallucination at the root by feeding the model exactly what it needs to stay grounded.
TL;DR
- LLMs are just token predictors — not magical thinkers.
- Prompt engineering is how we control the probability space and make output deterministic, relevant, and structured.
- Hallucinations happen — but most are preventable with better prompt design.
- RAG is the practical bridge between LLMs and real-world knowledge — don’t ship a production system without it.
Final Thought
If you’re building with LLMs and not investing time into prompt design, output evaluation, and RAG, you’re not building a product — you’re gambling.
These models are predictable when treated predictably.
Your interface is the prompt.