Table of Contents
Recap
In Part 1, we prepared our vector database by chunking and embedding a textbook, then tested simple similarity search queries. Now, we’ll take it a step further: build an interactive web app using Streamlit that allows users to ask questions, retrieves relevant documents, and answers them using an LLM.
Why Streamlit?
Streamlit is a fantastic Python framework for quickly building interactive apps with minimal code. It lets us create a chat interface that interacts live with the RAG system — no heavy frontend needed!
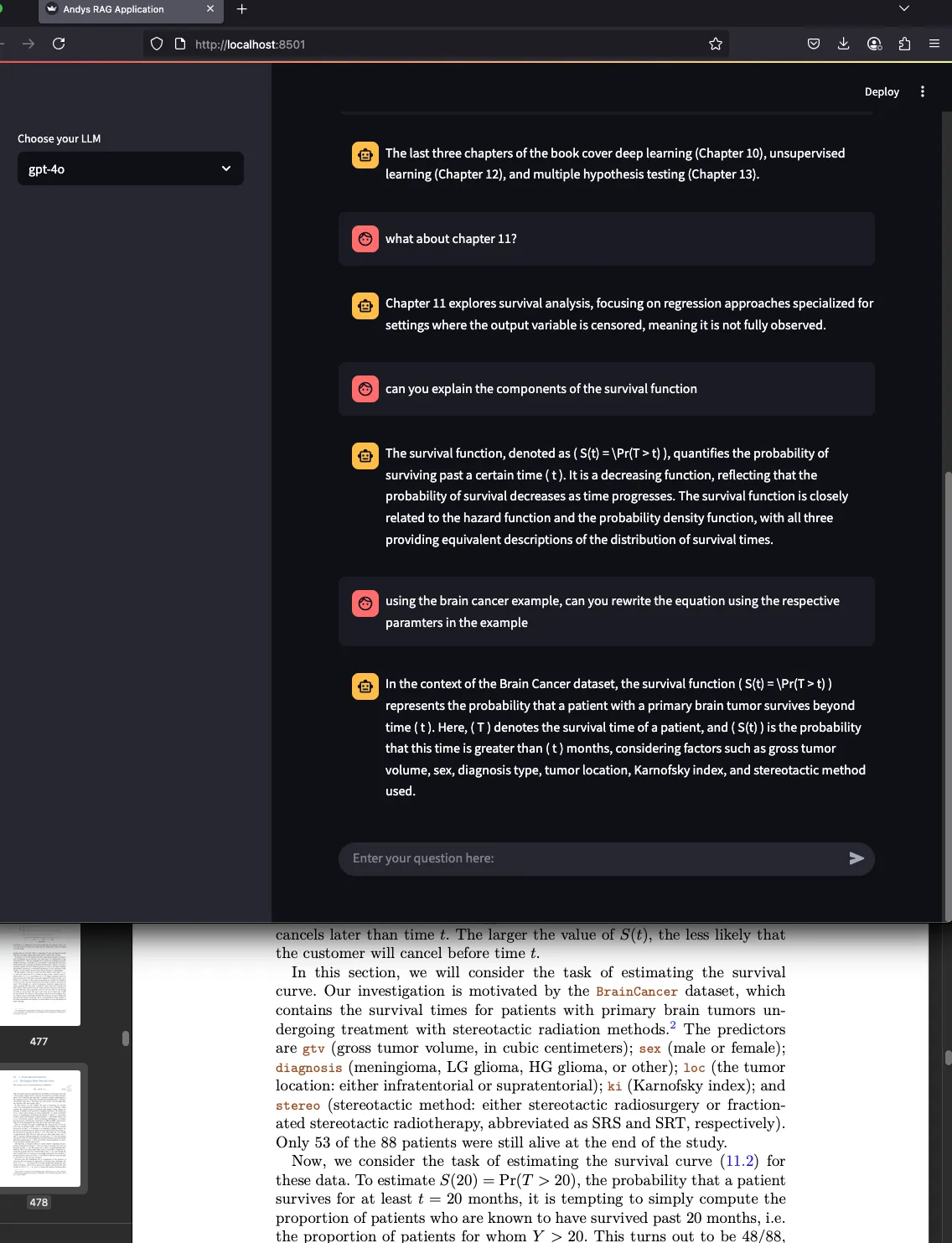
Step 1: Setup Environment and Dependencies
Before we dive in, make sure you have these packages installed:
pip install streamlit langchain langchain-chroma langchain-community pyyamlStep 2: Configure Your Streamlit App and Load Vector Store
We start by loading the vector database we created in Part 1 (statisticsKnowledge.db) and setting up the embeddings and LLM models.
import yaml
import os
import streamlit as st
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
# Streamlit page config
st.set_page_config(page_title="Custom RAG Application", layout="wide")
st.title("CUSTOM RAG APPLICATION")
# Sidebar to select which LLM to use
model_selection = st.sidebar.selectbox(
label="Choose your LLM",
options=["gpt-4o-mini", "gpt-4o","gpt-4.1"],
index=2
)Step 3: Manage Chat History
We want our chat to remember previous messages so the LLM can respond in context.
# Initialize chat history
msgs = StreamlitChatMessageHistory(key="langchain_msgs")
#Blank state
if len(msgs.messages) == 0:
msgs.add_ai_message("How can I help you?")
# Allow expanding to view current chat messages
view_msgs = st.expander("View the message contents in session state")
Step 4: Initialize the RAG Chain
This is the heart of the app: setting up the retriever and the chain that rewrites questions for context and fetches relevant documents from the vector DB.
def init_rag_chain():
embedding_client = OpenAIEmbeddings(model="text-embedding-3-small")
vector_db = Chroma(
embedding_function=embedding_client,
persist_directory= "./statisticsKnowledge.db",
collection_name="stats"
)
# Show how many docs are loaded
doc_count = vector_db._collection.count()
st.write(f"Number of documents in vectorstore: {doc_count}")
retriever = vector_db.as_retriever()
llm = ChatOpenAI(
model=model_selection,
temperature=0.7
)
# Prompt to rewrite user queries with chat history context for better retrieval
contextualize_q_system_prompt = """
Given the chat history and the latest user input,
rewrite it as a standalone question that captures the full context.
Do not answer the question, just rewrite it.
If it's already standalone, just return it as is.
"""
contextualize_q_prompt = ChatPromptTemplate.from_messages([
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
])
history_aware_retriever = create_history_aware_retriever(
llm,
retriever,
contextualize_q_prompt
)
# Prompt for the LLM to answer questions concisely from retrieved context
qa_system_prompt = """
You are to help with answering questions.
Use the retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Keep the answer short and concise.
{context}
"""
qa_prompt = ChatPromptTemplate.from_messages([
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}")
])
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
# Combine retriever + answer chain into a RAG chain that supports chat history
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
return RunnableWithMessageHistory(
rag_chain,
lambda session_id: msgs,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
custom_rag_model = init_rag_chain()Step 5: Display the Chat Interface and Process User Queries
Now we build the actual interactive UI:
# Display previous messages in chat
for msg in msgs.messages:
st.chat_message(msg.type).write(msg.content)
# Chat input widget
question = st.chat_input("Enter your question here:", key="query_input")
if question:
with st.spinner("Thinking ..."):
st.chat_message("human").write(question)
response = custom_rag_model.invoke(
{"input": question},
config={"configurable": {"session_id": "any"}}
)
st.chat_message("ai").write(response["answer"])Step 6: (Optional) View Raw Message History
Great for debugging or understanding the state behind the scenes.
with view_msgs:
"""
Message History initialized with:
```python
msgs = StreamlitChatMessageHistory(key="langchain_msgs")
```
Contents of `st.session_state.langchain_msgs`:
"""
view_msgs.json(st.session_state.langchain_msgs)And that’s it!
You now have a fully interactive Retrieval-Augmented Generation app powered by LangChain and Streamlit that:
-
Remembers conversation context,
-
Rewrites ambiguous queries for better retrieval,
-
Searches your proprietary knowledge base,
-
Answers questions concisely based on retrieved documents.
This app can be expanded with more data sources, advanced prompt tuning, or even plugged into a frontend framework.
Next steps
In future posts, we’ll explore:
-
Adding user authentication and personalization,
-
Scaling the vector database,
-
Deploying the app to the cloud, and
-
Exploring alternative retrievers and LLM providers.